前回のエントリー では動かし方のみ説明し、GrafanaスタックやMicrometerがどのように動いているのかについて触れていなかったので、これから何度かに分けて説明していきます。
第1回目はGrafana + Prometheusです。
Grafanaスタックの各プロダクトについて
説明に入る前に、Grafanaスタックになじみがない方(1ヶ月前の僕とか)も多いと思いますので、まずは簡単に各プロダクトのことを説明しておきます。
Grafana
https://grafana.com/oss/grafana/
GrafanaはGrafana Labsが開発している監視用のダッシュボードやアラート機能などを提供するUIです。Elastic Stackになじみ深い方にとっては「要するにkibana」と言うと説明が早いでしょうか。
GrafanaはPrometheus、Loki、Tempo、Elasticsearch、Zipkin、Jaegerなど多くのモニタリング系データストアの可視化に対応しています。ダッシュボードのカスタマイズ性などはKibanaの方が高機能なのですが、KibanaはElasticsearchにしか対応していないという点で違いがあります。
Prometheus
PrometheusはCPU使用率やメモリ消費量などのメトリクスを収集するデータストアです。多くのメトリクス用データストアと同様に、Prometheusもいわゆる時系列データストア(Time series datastore)で、タイムスタンプと共に数値やタグを保持することに特化しています。
ただ、多くのメトリクス用データストアはPush型である一方、PrometheusはPull型を採用しています。よくあるPush型のデータストアはクライアント側にデータ送信用のエージェント(CloudWatchやDataDogのエージェント、Metricbeatなど)がいてサーバにメトリクス情報を送るという流れですが、Prometheusは逆にPrometheus側がクライアントに情報を取りに行く流れになります。
Push型の監視に慣れ親しんだ僕としては、ハァ? Pull型? 逆に面倒くさくね? ってかサーバがクライアントを意識するとかあり得なくね? と思っていたのですが、今回使ってみて特にk8sで運用する際などには「なるほどpull型も良いもんだな」と考えが変わりました。その辺りは後で説明します。
Grafana LabsはPrometheusの開発を支援しており、Promethusの可視化では標準的にGrafanaが使われています。
https://grafana.com/oss/prometheus/
Loki
LokiはGrafana Labsが開発するログ収集用のデータストアです。ログ収集用のデータストアと言えばElasticsearchの一強で、CloudWatch LogsやDataDogなども追従してきましたが、ローカル環境にでもデプロイできるOSSプロダクトとして、ようやくElasticsearchのライバルが現れたのかなという印象です。
Elasticsearchが「全カラムをindexingする」というわりと富豪的なアプローチを採る一方で、Lokiは「少ないカラムだけindexingする」というアプローチなので、Elasticsearchの方が使い勝手や機能は上ですが、Lokiの方が少ないリソースで動かせるという点で分かれています。
Tempo
https://grafana.com/oss/tempo/
TempoはGrafana Labsが開発する分散トレーシング用のデータストアです。分散トレーシングと言えばZipkinが元祖であり一強で、Jaegerがそれに追従している状況です。
正直、分散トレーシングについてはZipkinが実現したアイデア自体が素晴らしいのであって、後発プロダクトも含めてあまり大きな優劣がないように思います(僕の分散トレーシングプロダクトに対する解像度が足りないだけかも知れませんが)
TempoはGrafana Labsが開発していてGrafanaとの親和性が高そうなので今回はこれを選びました。ちなみにGrafanaの説明で述べた通り、ZipkinやJaegerを使ってGrafanaで可視化することもできます。
Promtail
https://grafana.com/docs/loki/latest/clients/promtail/
PromtailはGrafana Labsが開発するLokiのためのログ収集エージェントです。Prometheusの発想を真似たPull型のエージェントであり、設定などもPrometheusとよく似ています。
ログ収集と言えばfluentdが君臨し、Elasticsearch用にはFilebeat(収集)とLogstash(加工)がよく使われていますが、Lokiと組み合わせて軽量に使うならPromtailが標準のようだったのでこれを使うことにしました。
Grafana Cloud
https://grafana.com/products/cloud/features/
Grafana CloudはモGrafanaを使ったニタリング環境をまとめて提供するSaaSで、Grafana、Prometheus、Loki、Tempoが利用できます。またログを送るためのGrafana AgentにはPromtailが含まれています。そういう点でも、今回選んだプロダクト群がGrafanaを利用する際の標準的なものだと考えて差し支えないと思います。
ちなみにAWSのマネージドサービスにもGrafanaとPrometheusはあるのですが、後発のLokiとTempoはありませんでした。現時点でマネージドサービスとしてGrafanaスタックを使いたいのであれば、Grafana Cloudを使うほうが良さそうです。
GrafanaスタックでSpring Bootアプリケーションを監視する
それでは実際にローカル環境(+ Docker)でGrafanaスタックを使ってSpring Bootアプリケーションのモニタリングを行う方法を説明します。
対象は前回のエントリーで紹介した spring-store-2022 です。
https://github.com/cero-t/spring-store-2022
メトリクス監視の構造は次の図のようになります。

/actuator/prometheus が追加され、そこにPrometheusが定期的にアクセスしてメトリクスを収集し、Grafanaでそのメトリクスを可視化するという流れです。
1. Grafanaの構築
Grafanaの各スタックはdocker-composeを使って起動します。
spring-store-2022/docker/docker-compose.yml のGrafanaの起動に関する部分は次の通りです。
services: grafana: image: grafana/grafana extra_hosts: ['host.docker.internal:host-gateway'] volumes: - ./config/grafana/datasources:/etc/grafana/provisioning/datasources:ro environment: - GF_AUTH_ANONYMOUS_ENABLED=true - GF_AUTH_ANONYMOUS_ORG_ROLE=Admin - GF_AUTH_DISABLE_LOGIN_FORM=true ports: - "3000:3000"
まず environment に次のような設定が入っていることに気づきます。
- GF_AUTH_ANONYMOUS_ENABLED=true - GF_AUTH_ANONYMOUS_ORG_ROLE=Admin - GF_AUTH_DISABLE_LOGIN_FORM=true
これはGrafanaにアクセスした際のログイン画面をスキップする設定です。ローカル環境でモニタリングする程度なら認証は要りませんから、これは入れておくと便利です。
そして ./config/grafana/datasources を /etc/grafana/provisioning/datasources にマウントしています。この datasources ディレクトリには datasource.yml があり、PrometheusやLokiなどをデータソースとして使う設定が記載されています。それぞれの設定の詳細については後ほど紹介します。
どうあれこれくらいでGrafanaは起動できます。
2. Spring BootアプリケーションにPrometheusのエンドポイント追加
続いて、Spring BootアプリケーションでActuatorとMicrometerを用いてPrometheus用のエンドポイントを作成します。
pom.xmlにActuatorとMicrometerを追加
Spring Bootアプリケーションのdependencyに spring-boot-starter-actuator と micrometer-registry-prometheus を追加します。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> <scope>runtime</scope> </dependency>
これだけで、actuatorのエンドポイントに /actuator/prometheus が追加されます。
ちなみにPrometheus用のMicrometerを追加したのでactuatorにエンドポイントが追加されましたが、ここで代わりに micrometer-registry-elastic を追加すると、actuatorのエンドポイントが追加される代わりに、Micrometerのメトリクス情報をElasticsearchに定期的に送るようになります。その辺りがpull型とpush型の違いですね。
application.propertiesに設定を追加
Spring Bootの application.properties にMicrometerの設定を少し追加します。
management.endpoints.web.exposure.include=*
management.metrics.distribution.percentiles-histogram.http.server.requests=true
management.metrics.tags.application=${spring.application.name}
management.endpoints.web.exposure.include=* は、actuatorのうち外部からアクセスできるエンドポイントを指定するものです。開発用なので全てのエンドポイントにアクセスできるようにしていますが、Prometheusを利用するだけなら management.endpoints.web.exposure.include=prometheus という指定だけで構いません。
management.metrics.distribution.percentiles-histogram.http.server.requests=true は、Micrometerのメトリクスにエンドポイントごとのレイテンシ(処理時間)を追加するものです。便利なメトリクスとしてよく使われているようです。
management.metrics.tags.application=${spring.application.name} はメトリクスを送るときにタグとして application にSpring Bootアプリケーションの名前(spring.application.name の値)を指定しています。メトリクスはアプリケーションごとに確認したいでしょうからほぼ必須のタグです。というかこれはデフォルトで送られるようになってても良いんじゃないかなと思うのですが。
アプリケーション側の設定はこれくらいです。
追加されたメトリクス
ここまでの設定をしてアプリケーションを起動した後、ブラウザやcurlコマンドなどで http://(アプリケーションのアドレス)/actuator/prometheus にアクセスしてみると、わりと凄い量のメトリクスが表示されます。
冒頭のみ抜粋しますが、このような形です。
# HELP process_files_max_files The maximum file descriptor count
# TYPE process_files_max_files gauge
process_files_max_files{application="bff",} 10240.0
# HELP process_uptime_seconds The uptime of the Java virtual machine
# TYPE process_uptime_seconds gauge
process_uptime_seconds{application="bff",} 15057.411
# HELP jvm_threads_peak_threads The peak live thread count since the Java virtual machine started or peak was reset
# TYPE jvm_threads_peak_threads gauge
jvm_threads_peak_threads{application="bff",} 43.0
# HELP jvm_threads_states_threads The current number of threads
# TYPE jvm_threads_states_threads gauge
jvm_threads_states_threads{application="bff",state="new",} 0.0
jvm_threads_states_threads{application="bff",state="runnable",} 11.0
jvm_threads_states_threads{application="bff",state="terminated",} 0.0
jvm_threads_states_threads{application="bff",state="waiting",} 12.0
jvm_threads_states_threads{application="bff",state="timed-waiting",} 9.0
jvm_threads_states_threads{application="bff",state="blocked",} 0.0
...
CPU使用率や、JavaVMのスレッド情報、ヒープ使用量、GCの詳細、HTTPエンドポイントへのリクエスト数など多岐にわたるメトリクスが表示されていて、これを毎秒収集してるとなるとデータサイズがとんでもないことになりそうだなと思ったのですが、いったん考えないことにしました。ハハハ。
3. Prometheusの構築
続いて、Prometheusの構築を行います。
docker-composeを用いたPrometheusの構築
Prometheusはdocker-composeを使って起動します。
docker-compose.ymlのうち、Prometheusの起動に関する部分のみピックアップします。
prometheus: image: prom/prometheus extra_hosts: ['host.docker.internal:host-gateway'] command: - --enable-feature=exemplar-storage - --config.file=/etc/prometheus/prometheus.yml volumes: - ./config/prometheus.yml:/etc/prometheus/prometheus.yml:ro ports: - "9090:9090"
ポイントは ./config/prometheus.yml を /etc/prometheus/prometheus.yml としてマウントして設定ファイルとして利用しているところくらいでしょうか。
--enable-feature=exemplar-storage はトレース情報のサンプルを保存するために必要な設定ですが、いったん今回は注目していないので説明を割愛します。
利用しているprometheus.ymlの内容は次のようになっています。
global: scrape_interval: 2s evaluation_interval: 2s scrape_configs: - job_name: "prometheus" static_configs: - targets: ["host.docker.internal:9090"] - job_name: "apps" metrics_path: "/actuator/prometheus" static_configs: - targets: [ "host.docker.internal:9000", "host.docker.internal:9001", "host.docker.internal:9002", "host.docker.internal:9003", "host.docker.internal:9004", "host.docker.internal:9005", "host.docker.internal:9006", "host.docker.internal:9010" ]
見て分かる通り、監視対象となるアプリケーションのアドレスとポートの一覧を列挙しています。ちょっとこれはどうなんでしょうか、こんなpull型エージェントを好きな人っているんでしょうか。
これでどうやってスケールアウト/スケールインするようなマイクロサービスを監視するんだよと思ったのですが、そういう環境ではそういう環境なりの設定方法があるので、また別に紹介します。
ここではひとまず「pull型エージェントはこういう風になるんだな」と思ってもらって構いません。
ここまで設定してPrometheusを起動すれば、Prometheusにメトリクスが収集されるようになります。
Prometheusの動作確認
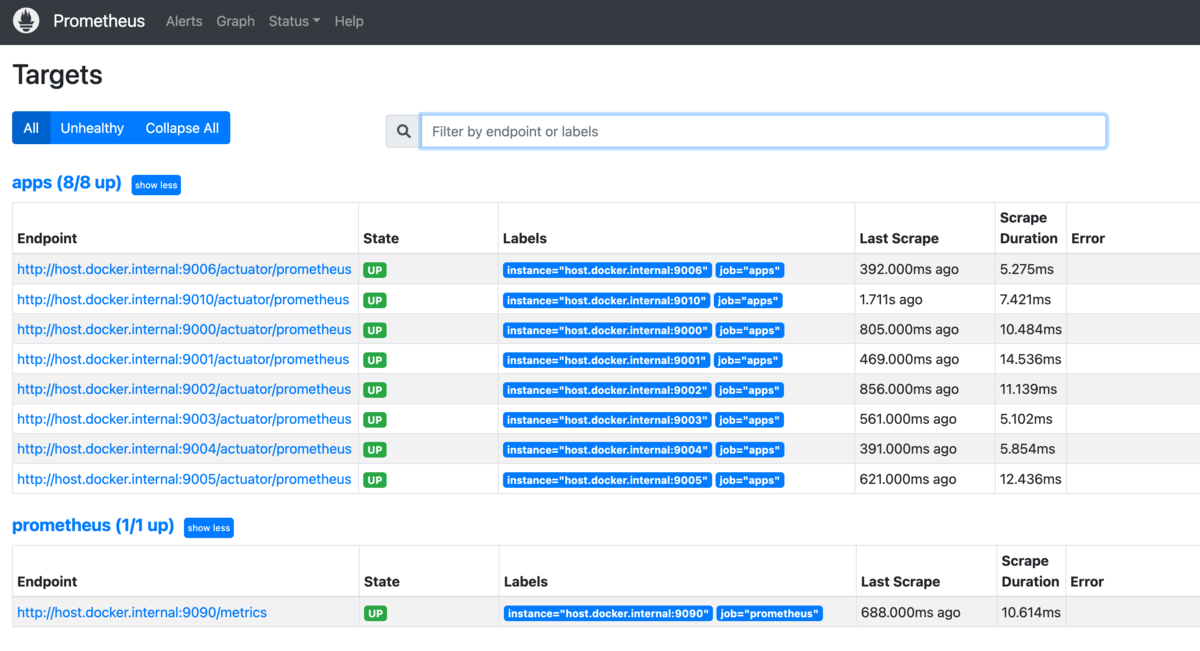
アプリケーションのメトリクスをPrometheusが正常に収集しているかどうかを確認するためは、Prometheusの /targets というエンドポイントにアクセスするのが良いでしょう。
ここにアクセスすると、Prometheusが収集している対象の一覧が表示されます。
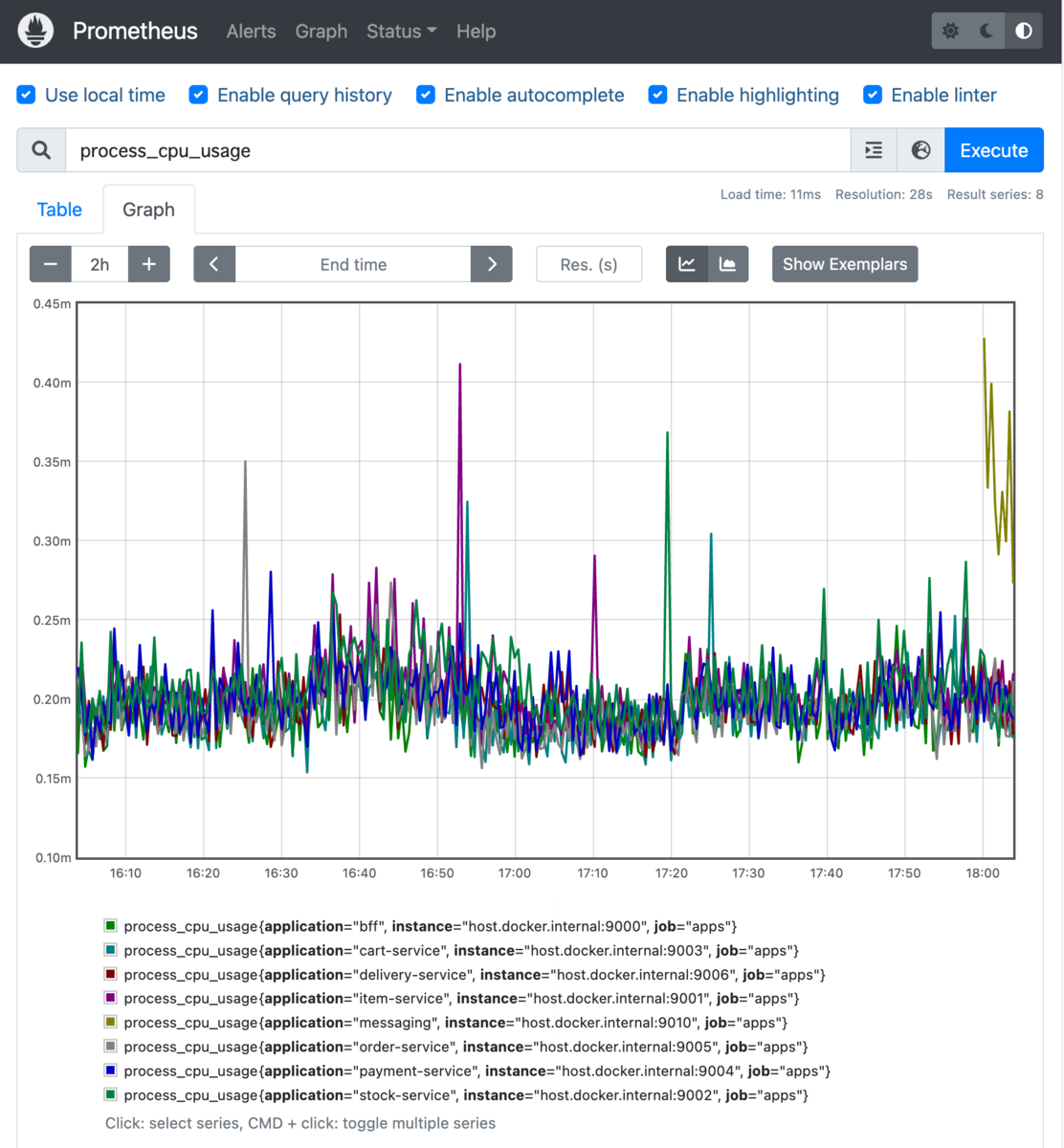
また、Graphビューで process_cpu_usage などを検索すると、収集したCPU使用率をグラフで表示できます。
4. GrafanaからPrometheusにアクセス
最後に、GrafanaからPrometheusを利用できるようにします。
GrafanaのデータソースにPrometheusを指定
GrafanaでPrometheusを可視化するためには、Grafana側でPrometheusをdatasourceとして設定する必要があります。Grafanaの構築のところで説明した通り datasources.yml にその設定があります。
datasources: - name: Prometheus type: prometheus access: proxy url: http://host.docker.internal:9090 editable: false jsonData: httpMethod: POST exemplarTraceIdDestinations: - name: trace_id datasourceUid: tempo
データソースとしてPrometheusを指定し、docker内の9090番ポートにアクセスするように記載しています。これでGrafanaがPrometheusを認識するようになります。
トレース情報のサンプルを tempo に送信するような設定も入っているのですが、これも今回は紹介しないので説明は割愛します。
ちなみにデータソースは datasources.yml で静的に設定するだけでなく、Grafanaの設定画面からでも追加できます。色々と試したい時は設定画面から追加した方が楽でしょう。
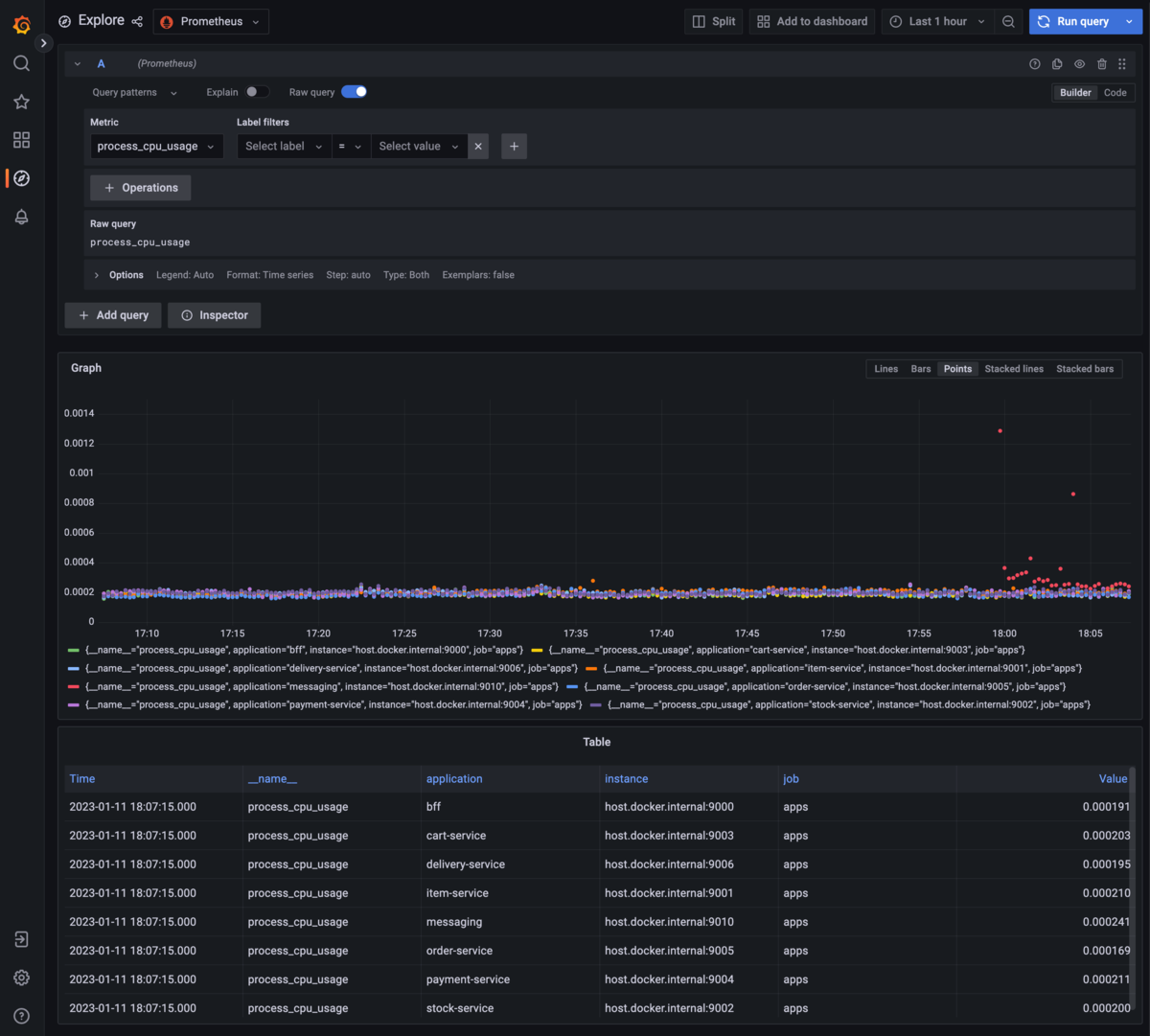
これでGrafanaのExploreでPrometheusを指定すると、Grafana上でPrometheusのメトリクスを検索、表示できるようになります。
Grafanaにダッシュボードを追加
ここまでの手順で、Spring Boot 3.0で作ったアプリケーションをGrafana + Prometheusでメトリクスを可視化できるようになりました。
ただここから自分で必要なデータを選んでダッシュボードを作っていくというのは、監視環境を構築した経験がないとなかなか難しいものです。そのため、Grafanaではコミュニティで作成したダッシュボードがたくさん提供されています。
ここでダッシュボードの一覧を「Spring Boot」で絞り込むと、2023年1月現在で52個のダッシュボードがヒットします。
https://grafana.com/grafana/dashboards/?search=Spring+Boot
その中でも最もよく使われているのが「JVM (Micrometer)」というものです。 grafana.com
導入はとても簡単で、まずダッシュボードのサイトでダッシュボードのIDを確認します。上の「JVM (Micrometer)」はIDが「4701」となっています。
それを確認したら、自分の環境に構築したGrafanaで左メニューのDashboardsにある「+Import」ボタンを押します。
「Import via grafana.com」の欄にIDを入力して右側にある「Load」ボタンを押します。
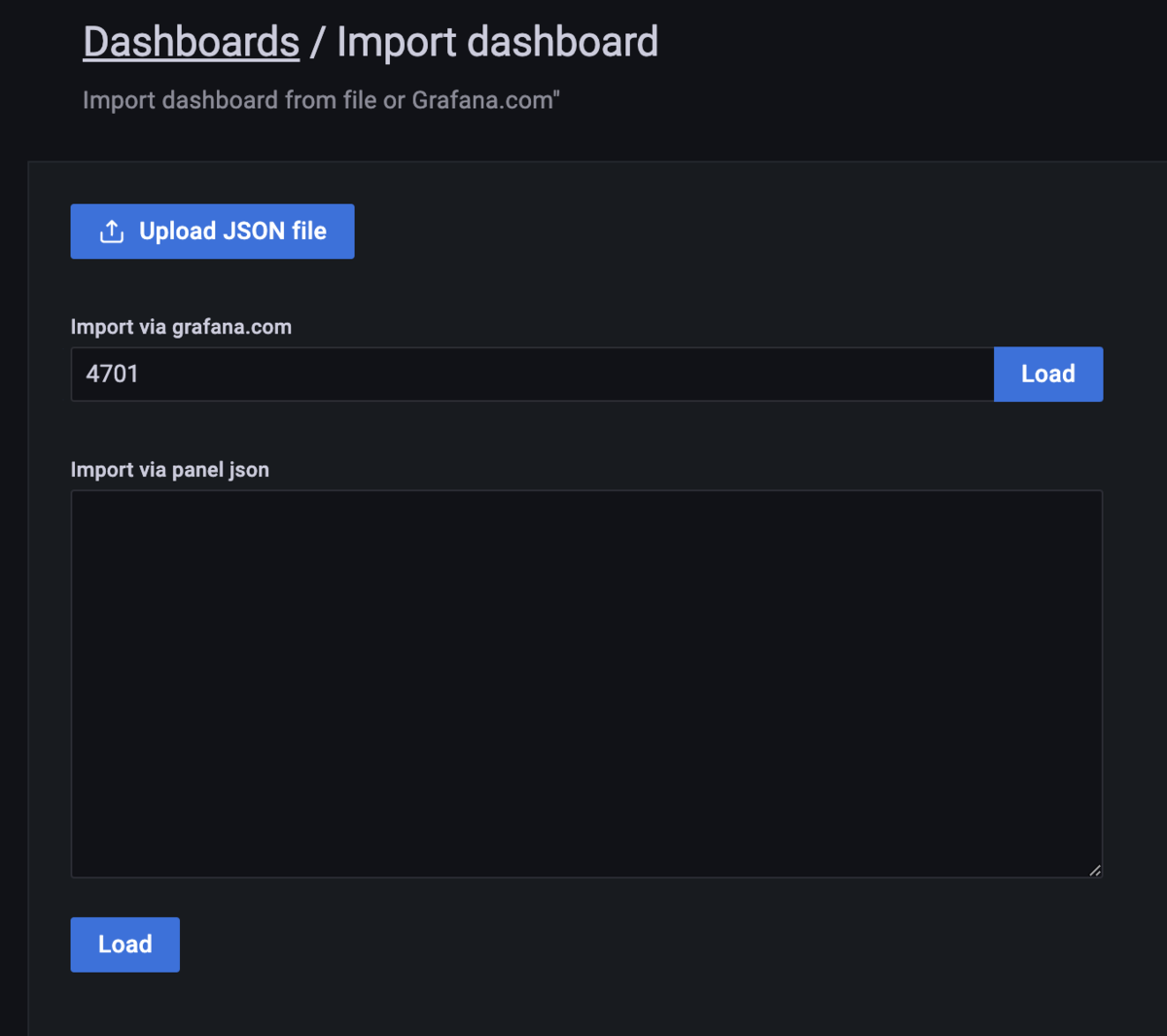
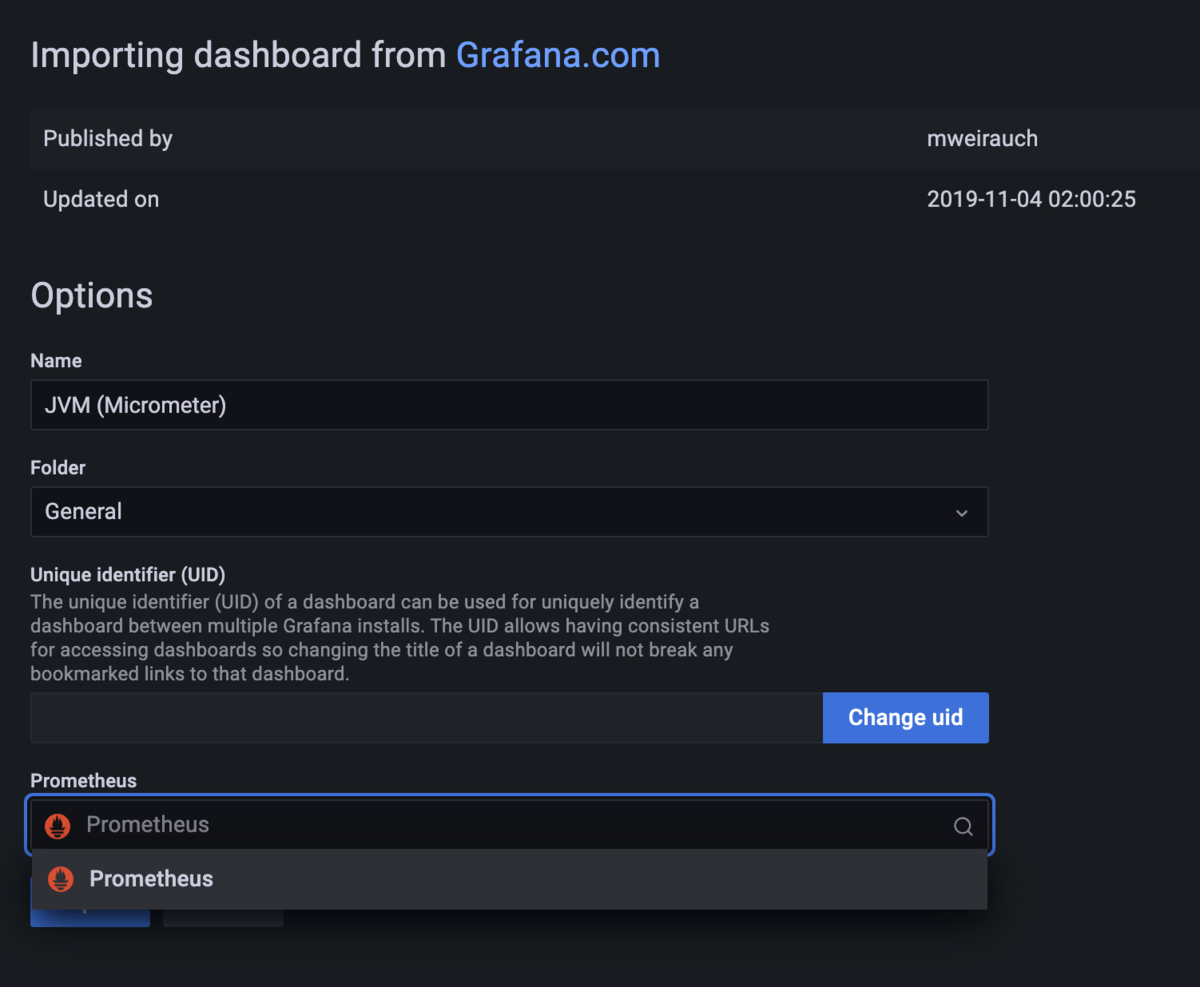
そしてPrometheusのデータソースとして、既に設定済みのPrometheusを指定して、「Import」ボタンを押します。
それだけで、カッコイイ感じのダッシュボードがインポートできました。
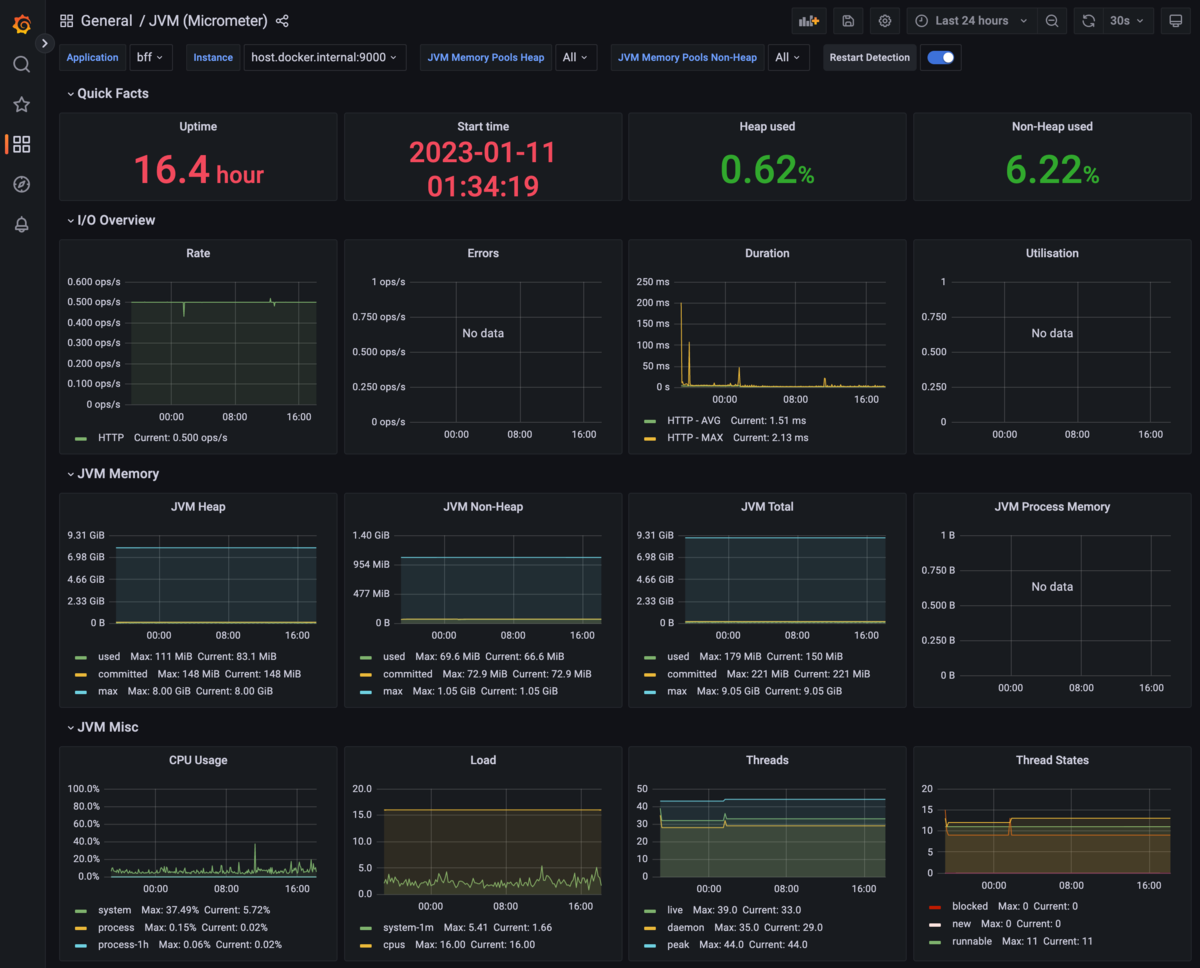
他にも様々なダッシュボードがあるため、好きなモノを探すもよし、自分でカスタマイズするのも良いでしょう。
まとめ
- Spring Bootアプリケーションに spring-boot-starter-actuator と micrometer-registry-prometheus を追加するとPrometheus用のエンドポイントが追加される
- GrafanaとPrometheusはdockerで簡単に利用できる
- GrafanaのデータソースとしてPrometheusを指定する必要がある
- コミュニティが作成したGrafana用のダッシュボードを利用できる
ぜひ、Grafanaで良い感じのダッシュボードを作ってみてください!