GrafanaスタックによるSpring Bootアプリケーション監視の詳細(その3 Grafana + Tempo編)
Grafanaスタックによるアプリケーション監視の第3回、今回はGrafana + Tempoです。ローカル環境(+ Docker)でGrafanaとTempoを使ってトレースの可視化を行います。
https://github.com/cero-t/spring-store-2022
トレース収集の構造
マイクロサービスにおいては特に「分散トレーシング」と呼ばれています。分散アプリケーションに対するトレーシングという意味であり、この図のように呼び出し階層や、それぞれの処理に掛かった時間などを可視化するために利用されます。
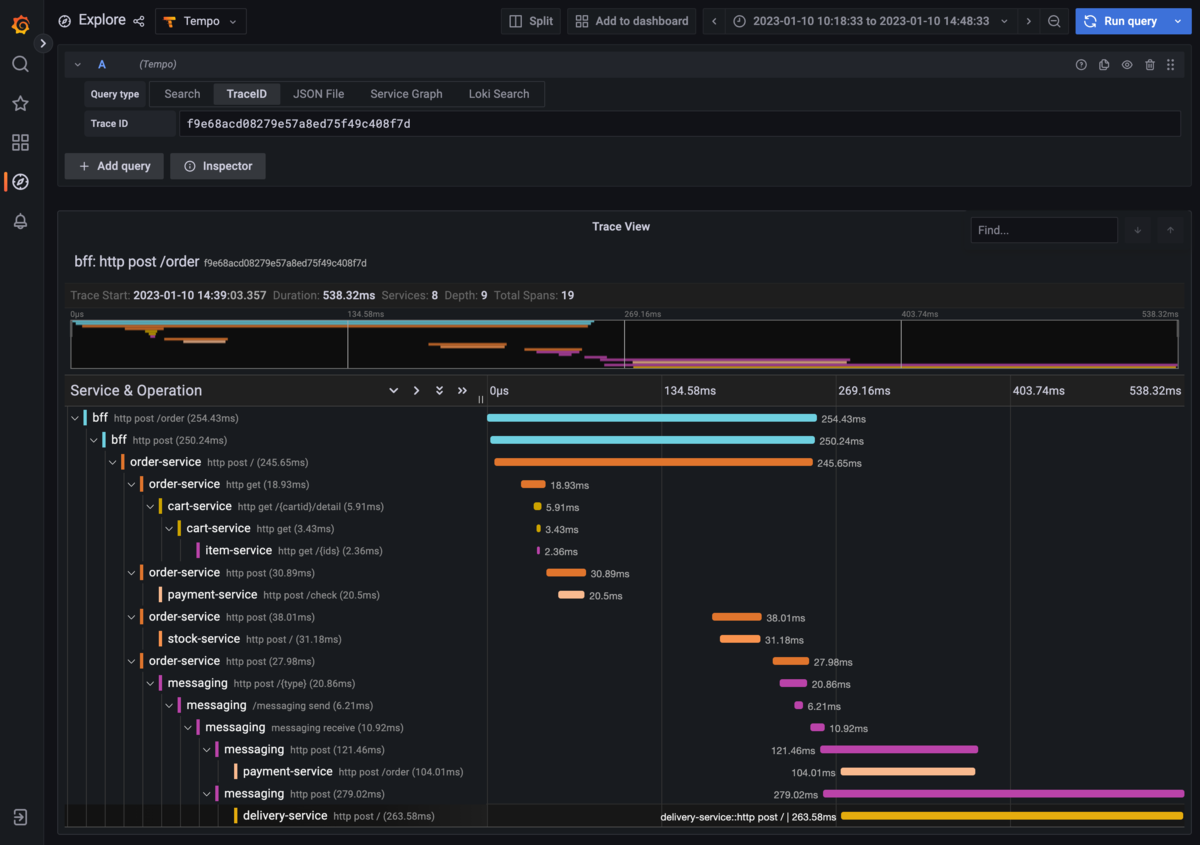
このような呼び出しの関係を作るためには、それぞれのアプリケーションが「誰から呼ばれたのか?」ということを認識する必要があります。そのために用いるのが「トレースID」です。
分散トレーシングにおいては、このトレースIDをアプリケーション間で伝搬させること、そしてそれぞれのアプリケーションからトレースストレージ(TempoやZipkinなど)にトレース情報を送ることの2つが不可欠です。
アプリケーション間のトレースIDの伝播
Spring Bootのアプリケーション間通信ではHTTPやAMQPなどが利用されます。この通信の際にトレースIDをHTTPヘッダやAMQPヘッダに追加することで伝播させます。
送信側のアプリケーションがHTTPヘッダにトレースIDを付与し、受信側のアプリケーションでそれを受け取り、またそこから別アプリケーションを呼び出す際にはHTTPヘッダにトレースIDを乗せるという形です。
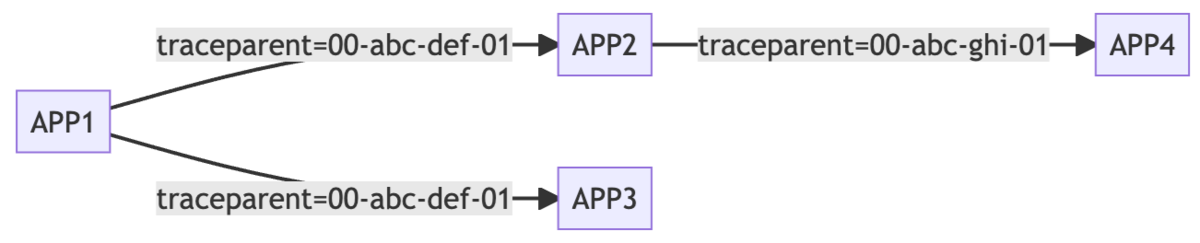
このヘッダは以前はライブラリごとに独自だったのですが、近年は traceparent というヘッダが W3C Trace-Context で規定され、これを使うライブラリやフレームワークがほとんどです。ただtraceparentヘッダの形式はライブラリごとに異なっていることもあり、完全に相互運用できるわけではないという現状です。
Spring Bootでは micrometer-tracing-bridge-otel か micrometer-tracing-bridge-brave というライブラリを利用することで、送信と受信ができるようになります。

トレース情報の送信
このようなトレース情報はアプリケーションが一時的に保持したうえで、トレースストレージ(TempoやZipkin、Jaegerなど)にHTTPやgRPCなどのプロトコルを用いて送信して集約します。
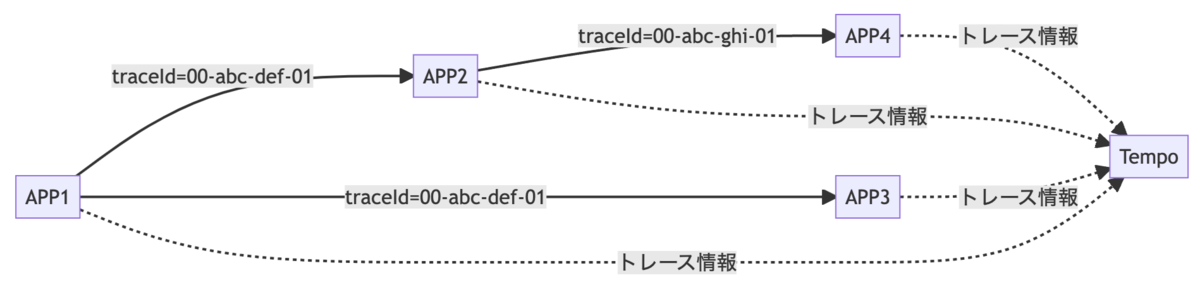
Spring Bootでは opentelemetry-exporter-zipkin か zipkin-reporter-brave を使うことでこのトレース情報を送信できるようになります。

ライブラリ名が「zipkin」なのにTempoに送れるのかと不思議に思うかも知れませんが、Tempoは(他のトレースストレージも同様ですが)Zipkin互換のAPIを備えており、Zipkin用のリクエストを受け取れるようになっています。
メトリクスやログに比べて少し構造が見づらくなりましたが、ひとまずは「トレースID伝播するためのライブラリと、トレース情報をストレージに送るためのライブラリは別なんだ」と理解してもらえれば問題ありません。
分散トレーシングについては、Elastic社のこの記事がとても分かりやすかったのでオススメです。
Tempoでトレースを収集する
それではTempoを使ってトレースを収集する手順を説明します。
1. Spring Bootアプリケーションからトレース情報を送る
まずはSpring Bootアプリケーションからトレース情報を送れるように関連ライブラリの追加などを行います。
トレースIDを伝播させる
まずはSpring Bootアプリケーション間でトレースIDを伝播できるようにします。
Spring Bootアプリケーションのdependencyに micrometer-tracing-bridge-otel を追加します。
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-tracing-bridge-otel</artifactId> <scope>runtime</scope> </dependency>
このライブラリを入れれば、RestTemplateなど(後述)で通信した際にOpenTelemetryのライブラリ群を使ってトレースIDの伝播が行われます。
MicrometerではOpenTelemetryのライブラリ以外にもBraveのライブラリを使った micrometer-tracing-bridge-brave というライブラリがあり、Spring Bootではいずれも利用することができるとドキュメントに記載があります。
両方試してみたところ特に何も違いはありませんでした。というか受信側と送信側でOpenTelemetryとBraveを混在させても良いくらいには互換性が保たれていました。
トレース情報を送信する
次にdependencyに opentelemetry-exporter-zipkin を追加します。
<dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-exporter-zipkin</artifactId> <scope>runtime</scope> </dependency>
これでアプリケーションがZipkin(Tempo)にトレース情報を送ることができるようになります。
ここでは代わりに zipkin-reporter-brave というBraveを利用してZipkinに送るライブラリも利用できます。他にも opentelemetry-exporter-otlp や opentelemetry-exporter-jaeger などがあるのですが、上で示したドキュメントに記載されていないライブラリは使えないようです。
正直、ライブラリの選択肢があることでちょっと混乱してしまいますね。Micrometer Tracingの前身であるSpring Cloud Sleuthの時も同じくちょっと混乱を招きがちだったので、ここは仕方ないところでしょうか。
トレース情報の送信割合を指定する
さらに、applicaiton.properties に設定を追加します。
management.tracing.sampling.probability=1.0
トレース情報をどれくらいの割合でサーバに送るかというものです。トレース情報はそれなりにボリュームがあるためデフォルトでは10%(0.1F)だけ送るようになっています。それだと手元で試すときには不便なので、開発中やデモの時には100%(1.0)にするのが王道です。
ちなみに実際に分散トレーシングを導入しているプロジェクトでは「エラーが起きた時に分散トレーシングを見て発生箇所を知りたい」という理由から、運用中でも送信割合を100%(1.0)にしています。エラーや、発生率の低い性能問題が起きた時に、そのトレース情報が収集されていないと意味がないですからね。僕も100%派です。
RestTemplateやWebClientのBeanを作る
Spring Webで RestTemplate を利用する場合は、RestTemplateBuilderをAutowiredさせてインスタンスを生成します。
@Bean RestTemplate restTemplate(RestTemplateBuilder builder) { return builder.build(); }
ここで単に return new RestTemplate(); としてしまうとOpenTelemetryのライブラリなどが利用されない素のRestTemplateとなってしまうためです。
WebClientについても同様です。
@Bean WebClient webClient(WebClient.Builder builder) { return builder.build(); }
Spring AMQPの場合はsetObservationEnabledをtrueにする
Spring WebやSpring Cloud Streamでは分散トレーシングが標準でできるようになっているのですが、Spring AMQPにおいては分散トレーシングの設定がデフォルトで無効化されています。RabbitTemplateとSimpleRabbitListenerContainerFactory(AbstractRabbitListenerContainerFactory)に setObservationEnabled というメソッドがあり、これを true にすることで有効化できます。
そこで BeanPostProcessor などの仕組みを用いてこの設定を有効化します。
@Configuration public class MessagingConfig implements BeanPostProcessor { @Override public Object postProcessAfterInitialization(@NonNull Object bean, @NonNull String beanName) throws BeansException { if (bean instanceof RabbitTemplate template) { template.setObservationEnabled(true); } else if (bean instanceof SimpleRabbitListenerContainerFactory factory) { factory.setObservationEnabled(true); } return bean; } }
この設定が必要なことがドキュメントには記載されていなかったので、見つけて設定をtrueにするまでエラく難儀しました。
issueを立てて開発者に聞いたところ、性能に対する懸念があるためデフォルトでfalseにしているとのことでした。その設計思想自体はわかるものの、このような設定が必要になるのはあまりに不便なので、できればSpring Boot全体で有効化/無効化できるような設定が欲しいところですね。
Spring AMQPプロジェクトは過去にもSpring Cloud Sleuth対応がしばらくされなかったこともあり、もしかしたら分散トレーシングが好きではないのかも知れませんね。
2. Tempoを構築する
続いてTempoを構築します。Tempoはdocker-composeを使って起動します。
docker-compose.ymlのうち、Tempoに関する部分が次の箇所です。
services: tempo: image: grafana/tempo extra_hosts: ['host.docker.internal:host-gateway'] command: [ "-config.file=/etc/tempo.yaml" ] volumes: - ./config/tempo-local.yaml:/etc/tempo.yaml:ro ports: - "14268" - "9411:9411"
設定ファイルとして ./config/tempo-local.yaml を使えるようマウントし、それを -config.file=/etc/tempo.yaml で利用していますね。
ポートは 14268 と 9411 の2つを利用しており、14268 はJaeger互換のAPIが動いているポートで、前回のLokiの構築のところで少し触れた通りLokiは自身のトレースをJaeger(実体はTempo)のエンドポイントに送るため、そのポートとして利用されます。いずれLokiはTempoのAPIでトレースを送るようになると思いますけどね。
また 9411 の方はZipkinのポートであり、TempoがこのポートでZipkin互換のAPIを提供します。アプリケーションからこのポートに向けてトレース情報を送るため、Docker外部にもポートを公開しています。
続いて tempo-local.yaml の内容について説明します。
server: http_listen_port: 3200 distributor: receivers: zipkin: storage: trace: backend: local local: path: /tmp/tempo/blocks search_enabled: true
上から順に「Tempoをポート3200として起動する」「Zipkin互換のAPIを動かす」「トレース情報をローカルストレージに保存する」「検索を有効にする」の4つが設定されています。
空っぽの設定のように見えるこの部分ですが
distributor: receivers: zipkin:
この設定を入れておかないとZipkin互換のAPIが動かないため、必ず入れるようにしてください。
また search_enabled を true にすることで、Tempoに対して条件を指定した検索が有効になります。これを設定しなければトレースIDによる検索しか行えません。デフォルトで有効化されてても良いと思うんですけどね。負荷やパフォーマンスに影響があるんでしょうかね。
3. GrafanaのデータソースにTempoを追加
過去に説明してきたPrometheusやLokiと同様に、GrafanaのデータソースにTempoを追加してGrafanaからTempoを参照できるようにします。
Grafanaのdatasources.ymlで設定しています。
datasources: - name: Tempo type: tempo access: proxy orgId: 1 url: http://tempo:3200 basicAuth: false isDefault: true version: 1 editable: false apiVersion: 1 uid: tempo jsonData: httpMethod: GET tracesToLogs: datasourceUid: 'loki' nodeGraph: enabled: true serviceMap: datasourceUid: 'prometheus'
データソースとしてTempoを指定し、url にTempoのアドレスを指定します。
それ以外の設定では、Grafanaのトレースからログにジャンプする設定や、アプリケーション同士の関連を可視化する設定を入れているのですが、バージョンの問題なのか何なのかうまく動いていないため(少し古いバージョンを使うと動くものもある)いったん説明は割愛します。
メトリクス・ログ・トレースの相互参照は開発が活発なところで、設定や挙動に変化があるため何か影響を受けているのかも知れません。
4. Grafanaでトレース情報を見る
ここまでの設定を終えてアプリケーションとGrafanaスタックを起動し、Grafanaにアクセスします。
ExploreでTempoを選択し、「Search」タブで「Service Name」でいずれかのサービスを選択して右上の「Run Query」ボタンを押すとトレースを検索することができます。
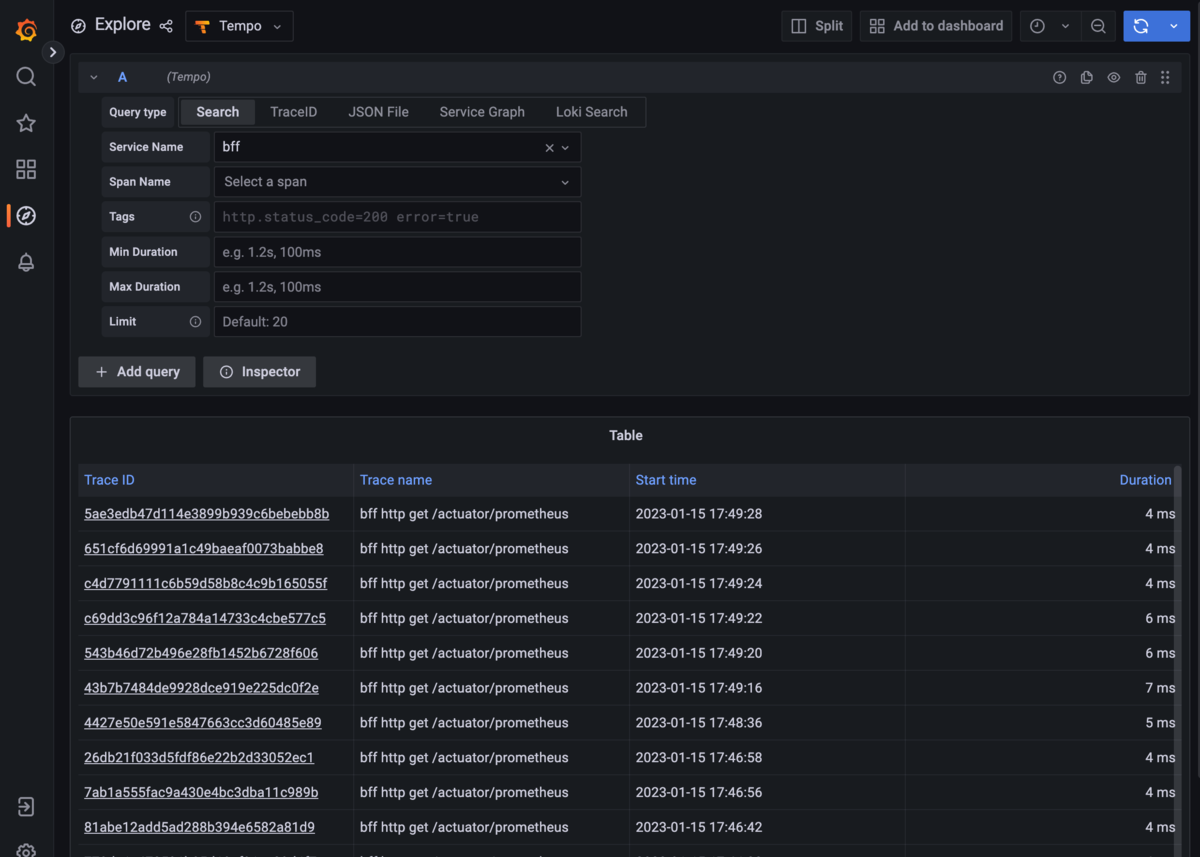
prometheusに対するアクセスばっかり出てきますね。これを送らないようにする方法も調べなきゃですね。
もう少し意味のあるトレースを見たいので、アプリケーション側で少し操作したうえで、「Span Name」で有効なURLを選択して検索しました。
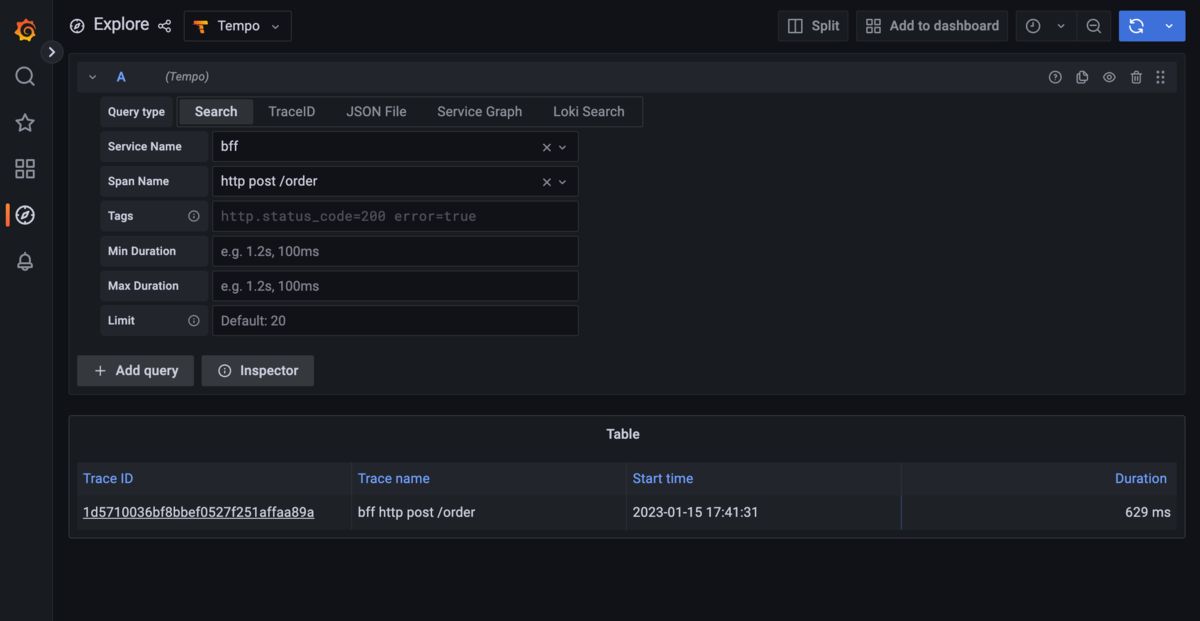
そしてTraceIDを選択すると、右側にトレースが表示されます。
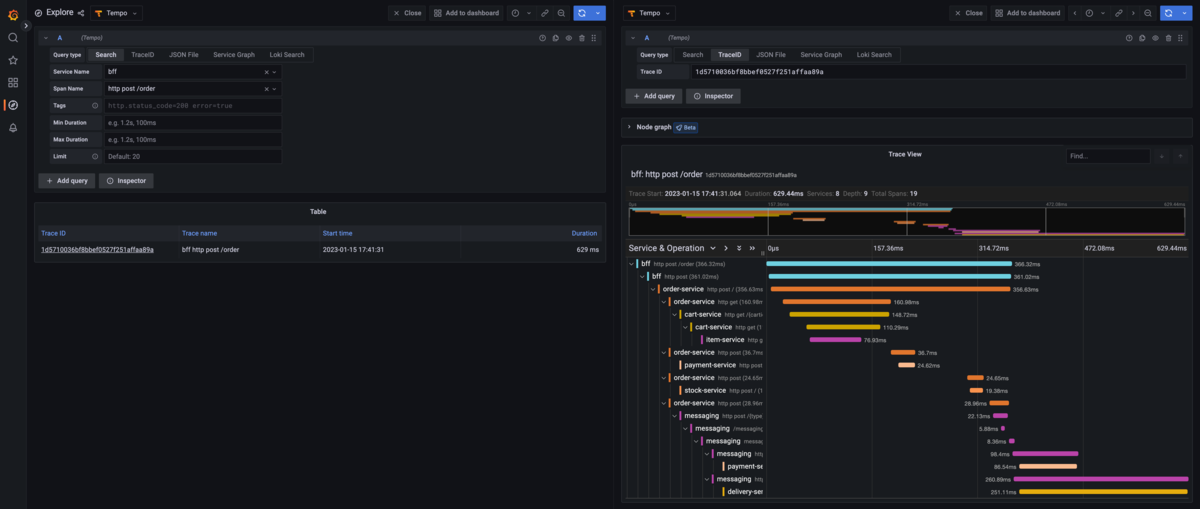
処理の呼び出し階層や、それぞれの処理に掛かった時間の詳細などを確認することができます。特にログなどを出していなくても、この情報を確認できるというのは便利なものですね。
また前回のLokiのところでも少し触れましたが、LokiとTempoの両方が設定されていると、LokiのログからTempoにジャンプすることもできるようになります。
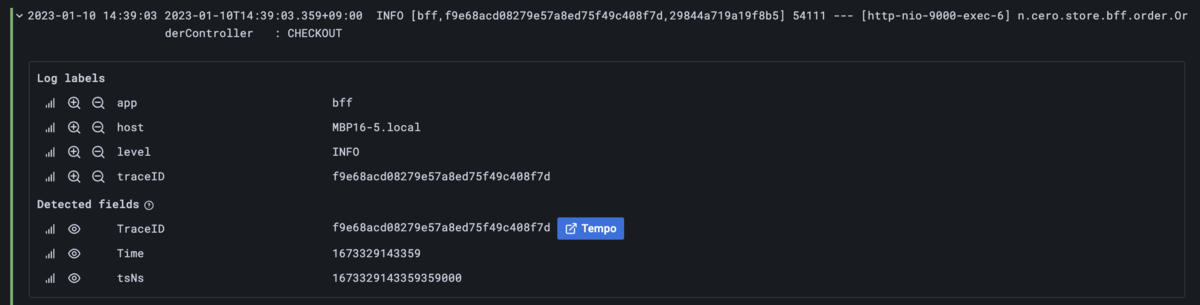
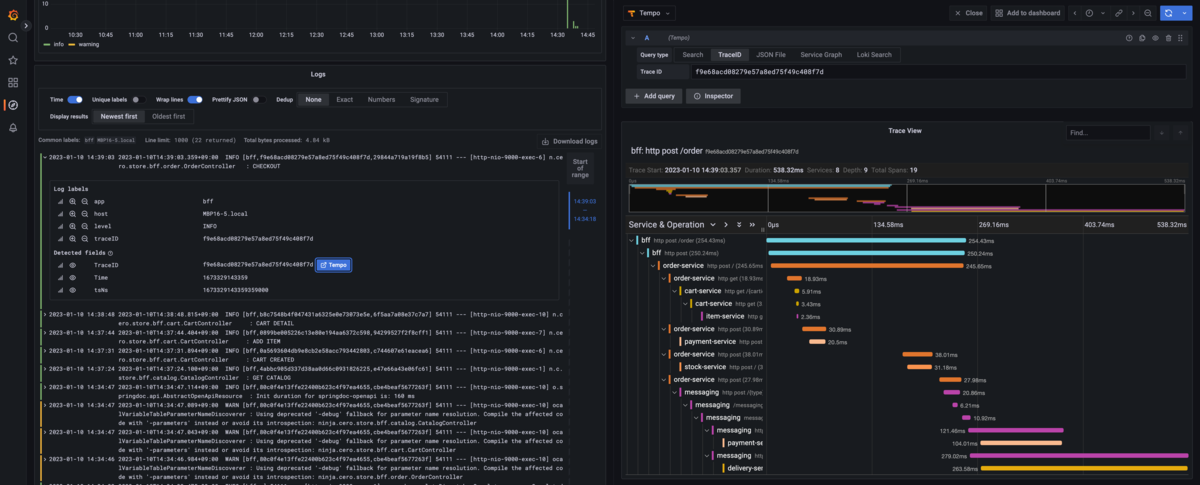
特にエラー発生時に出力するログにトレースIDが入っていれば、サービス呼び出しのどこで問題が起きたか捉えやすくなるので良いでしょう。
まとめ
- Spring Bootアプリケーションに
micrometer-tracing-bridge-otelかmicrometer-tracing-bridge-braveを入れればトレースIDの伝播ができる - Spring Bootアプリケーションに
opentelemetry-exporter-zipkinかzipkin-reporter-braveを入れればZipkinのエンドポイントにトレース情報を送るようになる - Spring Web、Spring Cloud StreamはデフォルトでトレースIDの伝播やトレース情報の送信が有効になっているが、Spring AMQPではコードで設定を有効化する必要がある
- GrafanaとTempoはdockerで簡単に利用できる
- Tempoの条件指定検索は設定で有効化する必要がある
- Grafana上でLokiのログからTempoのトレースにジャンプできる
ということで、3回に分けてGrafana、Prometheus、Loki、Tempoの設定や、Spring Bootアプリケーション側の対応について説明してきました。特に分散トレーシングについてはSpring Boot 3.0とMicrometer Tracingのおかげで必要な設定やライブラリが減っており、過去に比べて導入しやすくなったという印象です。
一部うまく動かない部分については、Grafana側のバージョンアップを確認しながら設定などを更新して対応したいと思います。ちょっと宿題として残ってしまいましたね。
さて次回は、これまで作った環境をk8s上に持っていきたいと思います。この連載は、もうちょっとだけ続くんじゃ。