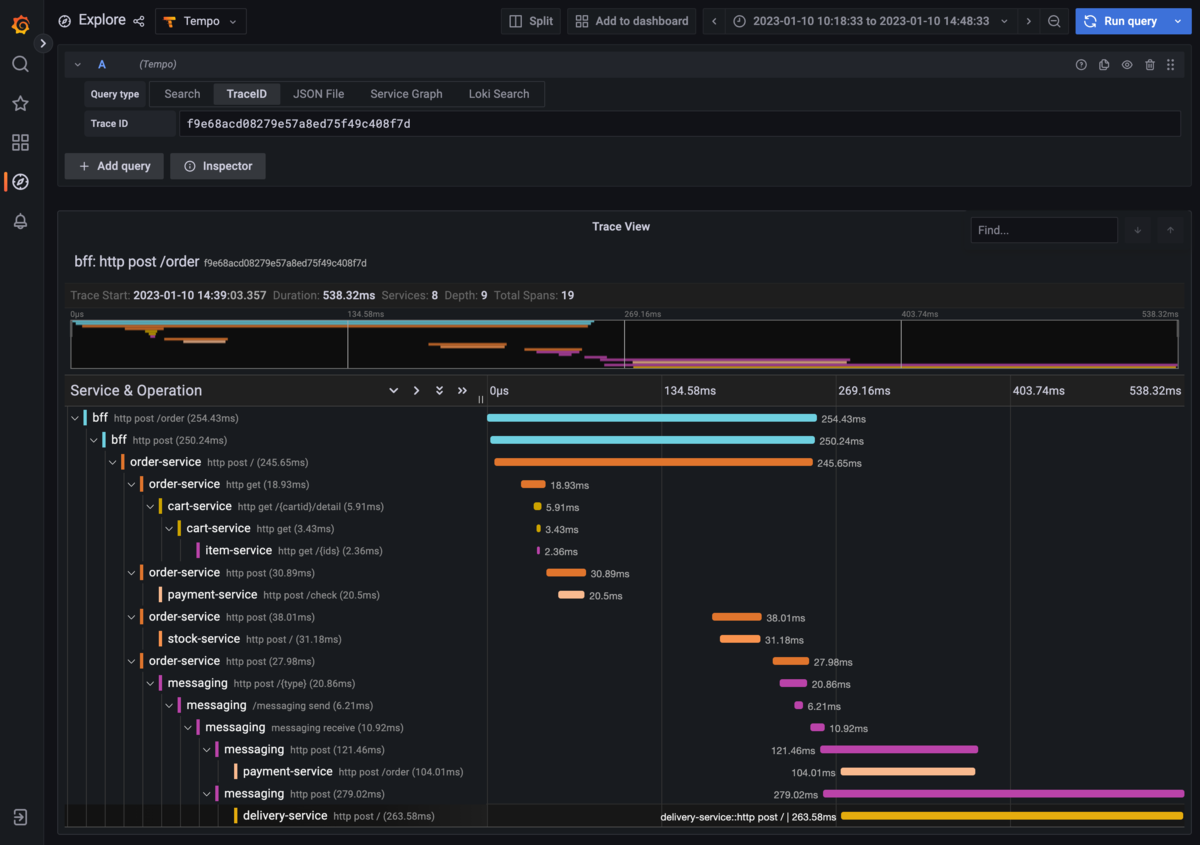
こんにちは、絶対にmvn installしたくないマンのcero_tです。しばらくブログはお休みです的なことを言ってたのに、今日も長文を書いてしまいました。
背景
Mavenで(Gradleでも)開発する時にはだいたいマルチモジュール構成にすると思うのですが、Spring Bootでマルチモジュール構成にした時に mvn spring-boot:run や mvn spring-boot:build-image をしようとするとエラーになってハマってしまったというお話です。
というか、いつも大体ハマってしまって解決できなくて、先にサブモジュールを mvn install を実行してから mvn spring-boot:build-image するなどして回避することが常なのですが、僕はこの mvn install が嫌いでして。
コンテナで動くCI環境ならまだしも、ローカル環境で mvn install を実行すると環境が汚れてしまう *1 し、そこに残ったゴミのせいで思わぬ挙動になってハマることもあるので、開発効率よりもハマらないことのほうが重要 と考える僕はこのコマンドが嫌いなのです。
そんなわけで、今回は mvn install をせずに mvn spring-boot:run や mvn spring-boot:build-image をするというお話です。
1. プロジェクトの構成
まずはサンプルにしたプロジェクトについて簡単に説明します。Spring Bootで開発している人にとっては「いつものやつ」なので読み飛ばしてもらっても大丈夫です。
親となる multi-module-example の下に my-library というライブラリのモジュールと my-service というSpring Bootアプリケーションのサービスがいるという構成です。
multi-module-example
├── .mvn
├── mvnw
├── pom.xml
├── my-library
│ ├── pom.xml
│ └── src
└── my-service
├── pom.xml
└── src
親子それぞれにpom.xmlを置いてモジュールとして定義しています。
ビルドは mvnw を使っておこないます。
1-2. 親pomの設定
multi-module-example のpom.xmlはこんな感じ。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/>
</parent>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>multi-module-example</artifactId>
<version>1.0.0</version>
<packaging>pom</packaging>
<name>multi-module-example</name>
<description>multi-module-example</description>
<modules>
<module>my-library</module>
<module>my-service</module>
</modules>
parentを spring-boot-starter-parent にして、子モジュールとして my-service と my-library を指定しています。マルチモジュール構成の時は、大体こうしますよね。
1-3. ライブラリモジュールのpomの設定
my-library のpom.xmlはこんな感じ。
<artifactId>my-library</artifactId>
<packaging>jar</packaging>
<name>my-library</name>
<description>my-library</description>
<parent>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>multi-module-example</artifactId>
<version>1.0.0</version>
<relativePath>../pom.xml</relativePath>
</parent>
parentを multi-module-example にします。親側で依存するライブラリとかを指定したいので、だいたいこういう相互参照にしますよね。
ちなみにライブラリの実装として、文字列を返すstaticメソッドを書いています。
public class MyLibrary {
public static String hello() {
return "Hello!";
}
}
特に実装について説明することはありません。
1-4. サービスモジュールのpomの設定
my-service のpom.xmlはこんな感じ。
<artifactId>my-service</artifactId>
<packaging>jar</packaging>
<name>my-service</name>
<description>my-service</description>
<parent>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>multi-module-example</artifactId>
<version>1.0.0</version>
<relativePath>../pom.xml</relativePath>
</parent>
<dependencies>
<dependency>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>my-library</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
やはりparentを multi-module-example にして、Spring Bootやライブラリのモジュールをdependencyに入れます。またSpring Bootアプリケーションとして起動するために、spring-boot-maven-plugin をビルドプラグインとして指定します。
またサービスの実装として、ライブラリを呼ぶようなWeb APIのエンドポイントを一つ設けています。
@SpringBootApplication
@RestController
public class MyService {
public static void main(String[] args) {
SpringApplication.run(MyService.class, args);
}
@GetMapping("/")
String hello() {
return MyLibrary.hello();
}
}
手抜きおぶ手抜きですが、ここは主題じゃないので。
1-5. IDEでの起動は問題なくできる
この構成で、IntelliJなどからMyServiceを実行すればアプリケーションが実行できます。
% curl localhost:8080
Hello!
はい、ここまでは当たり前です。
1-6. package もできる
この構成で、Executable JARを作って実行することもできます。
$ ./mvnw clean package
[INFO] multi-module-example ............................... SUCCESS [ 0.057 s]
[INFO] my-library ......................................... SUCCESS [ 0.527 s]
[INFO] my-service ......................................... SUCCESS [ 0.427 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1.179 s
[INFO] Finished at: 2022-12-28T09:25:39+09:00
[INFO] ------------------------------------------------------------------------
ビルドに成功したので、起動します。
$ java -jar my-service/target/my-service-1.0.0.jar
2022-12-28T09:27:39.691+09:00 INFO 64023 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2022-12-28T09:27:39.699+09:00 INFO 64023 --- [ main] n.cero.example.multi_module.MyService : Started MyService in 1.155 seconds (process running for 1.384)
問題なく起動しました。
% curl localhost:8080
Hello!
もちろんアクセスすれば正常応答が返ります。
こんな風にふつうにビルドできて動くので、この時点ではあまり疑問を持つことはありません。
2. どんな問題が起きるのか
それでは、問題を再現させます。
2-1. spring-boot:run できない
Mavenコマンドを使って直接Spring Bootのアプリケーションを起動するには spring-boot:run を使います。ただ親子構造を持っている場合には、親側のディレクトリで -pl (--projects) オプションをつけて実行します。
% ./mvnw spring-boot:run -pl my-service
[INFO] -------------< ninja.cero.example.multimodule:my-service >--------------
[INFO] Building my-service 1.0.0
[INFO] --------------------------------[ jar ]---------------------------------
[WARNING] The POM for ninja.cero.example.multimodule:my-library:jar:1.0.0 is missing, no dependency information available
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.194 s
[INFO] Finished at: 2022-12-28T09:36:03+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project my-service: Could not resolve dependencies for project ninja.cero.example.multimodule:my-service:jar:1.0.0: ninja.cero.example.multimodule:my-library:jar:1.0.0 was not found in https://repo.maven.apache.org/maven2 during a previous attempt. This failure was cached in the local repository and resolution is not reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
はい失敗しました。依存している my-library:jar:1.0.0 がないぞと。親子構造で指定しているのに、気が利かないわね。
・・・なんて言わず -pl オプションは大体 -am (--also-make) オプションと一緒に実行します。依存しているモジュールがあればそれも一緒にビルドするというオプションです。
% ./mvnw clean spring-boot:run -am -pl my-service
[INFO] multi-module-example ............................... FAILURE [ 0.199 s]
[INFO] my-library ......................................... SKIPPED
[INFO] my-service ......................................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.482 s
[INFO] Finished at: 2022-12-28T09:38:29+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.springframework.boot:spring-boot-maven-plugin:3.0.0:run (default-cli) on project multi-module-example: Unable to find a suitable main class, please add a 'mainClass' property -> [Help 1]
はい失敗しました。親pomである multi-module-example に、Spring Bootアプリケーションを起動するための main クラスがないぞと。
あるわけないやろ! 親pomやぞ、っていうか <packaging>pom</packaging> やぞ、良い感じにスキップしてくれや!!
というかこの挙動って前からでしたっけ? ライブラリ側にmainクラスがないと怒られるならまだしも、親pomにないと言われるのはちょっと解せないですね。
解決は後ほど試みるとして、一旦、もう一つコマンドを試してみます。
2-2. spring-boot:build-image できない
Mavenコマンドを使ってSpring Bootのアプリケーションのコンテナイメージを作るために spring-boot:build-image を使います。フットプリントが小さく、オプションなども良い感じにつけてくれると評判のbuildpacksを使ったイメージ作成コマンドです。
先ほどと同じように -pl (--projects) と -am (--also-make) オプションをつけて実行します。
% ./mvnw clean spring-boot:build-image -am -pl my-service
[INFO] multi-module-example ............................... SUCCESS [ 0.205 s]
[INFO] my-library ......................................... FAILURE [ 4.931 s]
[INFO] my-service ......................................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 5.406 s
[INFO] Finished at: 2022-12-28T09:53:05+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.springframework.boot:spring-boot-maven-plugin:3.0.0:build-image (default-cli) on project my-library: Execution default-cli of goal org.springframework.boot:spring-boot-maven-plugin:3.0.0:build-image failed: Error packaging archive for image: Unable to find main class -> [Help 1]
はい失敗しました。ライブラリ my-library に main クラスがないぞと。
いや、そうなるからライブラリ側には spring-boot-maven-plugin を指定してないんですけど…という気持ちでいっぱいになるのですが、mvn spring-boot:build-image を実行したからには -am で伴ってビルドされるモジュール側もアプリケーションのコンテナイメージを作られてしまう(そして失敗してエラーになる)みたいです。
3. 解決のためのトライ&エラー
それでは仮説を立てつつトライ&エラーをしながら問題の解決に向かいます。
まずはより重要な spring-boot:build-image の方から取り組みます。
3-1. ライブラリの spring-boot-maven-plugin をスキップする
ライブラリ側のビルドイメージを作ろうとしてエラーが出ているのですが、それなら spring-boot-maven-plugin の実行をスキップしてしまえば良いのではないかと考えました。
my-libary のpom.xmlに次のような設定を追加します。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
これで spring-boot-maven-plugin の実行はスキップされます。
ところが、ところがですよ?
% ./mvnw clean spring-boot:build-image -am -pl my-service
[INFO] --- maven-jar-plugin:3.3.0:jar (default-jar) @ my-library ---
[INFO] Building jar: /Users/shin/GitHub/multi-module-example/my-library/target/my-library-1.0.0.jar
[INFO]
[INFO] --- spring-boot-maven-plugin:3.0.0:repackage (repackage) @ my-library ---
[INFO]
[INFO] <<< spring-boot-maven-plugin:3.0.0:build-image (default-cli) < package @ my-library <<<
[INFO]
[INFO]
[INFO] --- spring-boot-maven-plugin:3.0.0:build-image (default-cli) @ my-library ---
[INFO]
(略)
[INFO] multi-module-example ............................... SUCCESS [ 0.227 s]
[INFO] my-library ......................................... SUCCESS [ 0.441 s]
[INFO] my-service ......................................... FAILURE [ 0.715 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1.671 s
[INFO] Finished at: 2022-12-28T10:11:51+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project my-service: Could not resolve dependencies for project ninja.cero.example.multimodule:my-service:jar:1.0.0: Could not find artifact ninja.cero.example.multimodule:my-library:jar:1.0.0 in central (https://repo.maven.apache.org/maven2) -> [Help 1]
my-library のビルドには成功したようなのに、my-service のビルド時に my-library が見つからないというエラーが発生します。
ビルド自体がスキップされてしまったのかと思って念のため確認しましたが my-library/target/ にはきちんと my-library-1.0.0.jar ができあがっています。それなのにそれなのに、なぜか参照されないのです。
ライブラリ側で spring-boot-maven-plugin の実行をスキップした場合、たとえビルドに成功していても、spring-boot-maven-plugin のコンテキストでは成果物を認識できず spring-boot:build-image では成果物がないかのように扱われている、と考えれば良いのでしょうかね。
3-2. ライブラリから親pomへの参照をやめる
それならばと、ライブラリ側から親pomへの参照をやめることにしました。ライブラリは別にSpringに関連する処理を書いているわけではないので、特に親pom、さらにはその親の spring-boot-starter-parent を参照する必要もありません。
my-library のpom.xmlを次のように書き換えました。
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>my-library</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>my-library</name>
<description>my-library</description>
<properties>
<mavencompilersource>17</mavencompilersource>
<mavencompilertarget>17</mavencompilertarget>
</properties>
親pomへの参照を削除しました。
この状態で ./mvnw clean package すると、正常にビルドが通ることは確認できています。
ところが、ところがです。
% ./mvnw clean spring-boot:build-image -am -pl my-service
[INFO] my-library ......................................... SKIPPED
[INFO] multi-module-example ............................... SKIPPED
[INFO] my-service ......................................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.994 s
[INFO] Finished at: 2022-12-28T10:26:00+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] No plugin found for prefix 'spring-boot' in the current project and in the plugin groups [org.apache.maven.plugins, org.codehaus.mojo] available from the repositories [local (/Users/shin/.m2/repository), central (https://repo.maven.apache.org/maven2)] -> [Help 1]
spring-boot: できるプラグインが見つからないというのです。なぜでしょうか。仮説をいくつか立ててみました。
- 何らかの理由で親pomが
spring-boot: を実行するためのプラグインを見失った
- 親子構造の場合は、親と子は相互参照しないといけない
- ビルド対象はすべて
spring-boot-starter-parent (の中にある何か)に依存しなければならない
ひとつずつ検証していきましょう。
3-2 (1) 親pomが spring-boot: を実行するためのプラグインを見失った?
親pom側で spring-boot-maven-plugin を入れてみました。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
これでも結果は全く変わりません。別に親pomが spring-boot: プラグインを参照できていないことが理由というわけではなさそうです。
3-2 (2) 親子構造の場合は、親と子は相互参照しないといけない?
マルチモジュール構成では、親と子は相互に参照しなければならないのでしょうか。
ただそれならば ./mvnw clean package コマンドも通らないはずです。実際にはビルドに成功して実行可能な成果物ができていました。
つまり、親子は相互参照にしなければならないわけではありません。
3-2 (3) ビルド対象はすべて spring-boot-starter-parent に依存しなければならない?
親子関係がなくとも、親が spring-boot-starter-parent であれば良いのでしょうか。
my-library のpom.xmlを次のように書き換えてみます。
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>my-library</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/>
</parent>
<name>my-library</name>
<description>my-library</description>
これでビルドしてみましょう。
% ./mvnw clean spring-boot:build-image -am -pl my-service
[INFO] my-library ......................................... FAILURE [ 0.421 s]
[INFO] multi-module-example ............................... SKIPPED
[INFO] my-service ......................................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.682 s
[INFO] Finished at: 2022-12-28T10:37:48+09:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.springframework.boot:spring-boot-maven-plugin:3.0.0:run (default-cli) on project my-library: Unable to find a suitable main class, please add a 'mainClass' property -> [Help 1]
エラーが変わって my-library に main クラスがないというエラーになりました。
そうすると、すべてのビルド対象が spring-boot-starter-parent に依存しなければいけないという仮説は、的外れではなさそうです。*2
4. 解決編
さて、紳士淑女の皆さま、お待たせしました。ここからは解決編です。すべての手がかりは提示されました。
エラーは自明。ただし、私はこう問いかけましょう。はたして、あなたは私の解決策を推理することができますか?
要点は3つ。勘のいい皆さんはもうおわかりですね?
ライブラリ側の spring-boot-maven-plugin が有効な状態では spring-boot:build-image でライブラリのアプリケーションイメージを作ろうとしてしまい、必ず失敗する
ライブラリ側のビルドで spring-boot-maven-plugin をスキップすると、spring-boot:build-image では成果物はなかったと見なされてしまい、後続のサービス側のビルド時にライブラリの成果物を見つけることができない
すべてのビルド対象が spring-boot-starter-parent に依存しなければいけない
これらの問題を解決する方法は何なのか。ヒントは mvn package は正常に動くということ…
@cero_t でした。
4-1. spring-boot:build-image を解決する
あまり視聴率の高くないドラマのセリフをパクっても、まるで滑ったかのような感じになるので難しいですね。
そんなわけで解決策ですが、まずは spring-boot:build-image の方から解決します。
ライブラリ側 my-library のpom.xmlをこのような形にします。
<artifactId>my-library</artifactId>
<packaging>jar</packaging>
<name>my-library</name>
<description>my-library</description>
<parent>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>multi-module-example</artifactId>
<version>1.0.0</version>
<relativePath>../pom.xml</relativePath>
</parent>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
spring-boot-starter-parent を使う必要がある以上、spring-boot-maven-plugin はスキップする設定を入れるしかありません。parentは親pomでも spring-boot-starter-parent でもどちらでも構わないのですが、利便性を考えると親pomを参照する方が好きです(この件は後述します)
そして実行コマンドは次のようになります。
./mvnw clean package spring-boot:build-image -am -pl my-service
spring-boot:build-image の前に package を入れています。
こうすれば package でライブラリとサービスのビルドをおこなって必要な成果物が揃い、続いてspring-boot:build-image でビルド済みの成果物を使ってイメージ作成のみが行われるわけです。
ちなみに1コマンドで済ませることが必要であり、次のように2コマンドに分けると動きません。
./mvnw clean package -am -pl my-service
./mvnw spring-boot:build-image -am -pl my-service
この場合も spring-boot:build-image でサービス側をビルドしようとした時に「ライブラリ側の成果物はなかった」と認識してしまうようです。2つめのコマンドの -am オプションを外しても変わりません。
spring-boot: の挙動に少し怪しいところを感じなくはないのですが、どうあれ1コマンドで package でビルドまで済ませてから spring-boot:build-image でイメージを作るところまでやりきれば良いということです。
4-2. spring-boot:run を解決する
仕組みがおおむね把握できたところで、続けて spring-boot:run の解決もしましょう。
こちらは親pomの main クラスを探そうとしてしまうことが問題になります。
ここまで見てきた挙動を踏まえると、解決策は2つあります。
4-2 (1) 親pomの spring-boot-maven-plugin をスキップする
一つ目は、親側のpomで spring-boot-maven-plugin をスキップすることです。次のような設定になります。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/>
</parent>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>multi-module-example</artifactId>
<version>1.0.0</version>
<packaging>pom</packaging>
<name>multi-module-example</name>
<description>multi-module-example</description>
<modules>
<module>my-library</module>
<module>my-service</module>
</modules>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
ただし親pomでこのように定義すると、子側のライブラリ2つにも同じ設定が引き継がれることになります。そのため先ほど spring-boot:build-image のために my-library に入れた同様の設定は必要なくなります。
逆にサービス側 my-serivce では次のように設定を上書きする必要があります。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<skip>false</skip>
</configuration>
</plugin>
</plugins>
</build>
skipがfalseだからスキップしない、というのは二重否定のようでちょっと分かりづらい気もしますが、この方針での回避策としてはこの形になります。
4-2 (2) 子側から親pomへの参照をやめる
もう一つは、子側、つまりライブラリ側とサービス側の両方について、<parent> を親pomではなく spring-boot-starter-parent にしてしまうことです。そうすれば子から親への参照はなくなるわけですから spring-boot:run する時に、参照先の親側で spring-boot:run することもなくなります。
その場合、親側のpomで <dependencyManagement> を使って依存するモジュールのバージョンを一括で指定することはできなくなります。もし依存するモジュールのバージョンを指定したい場合には、依存を管理する専用のモジュールを別途作る必要があります。
具体的にはこのような設定のモジュールを作ります。
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>dependency-management</artifactId>
<version>1.0.0</version>
<packaging>pom</packaging>
<name>dependency-management</name>
<description>dependency-management</description>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.github.loki4j</groupId>
<artifactId>loki-logback-appender</artifactId>
<version>1.3.2</version>
</dependency>
</dependencies>
</dependencyManagement>
そして、それをアプリケーション側の <dependencyManagement> で利用する形になります。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.github.loki4j</groupId>
<artifactId>loki-logback-appender</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>ninja.cero.example.multimodule</groupId>
<artifactId>dependency-management</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
こちらの方が作るファイルが増えますが、Spring BootやSpring Cloudでも採られている手法ですし、どちらかと言えばこちらの方が真っ当な方法ですよね。
まとめ
- 4-2 の (1) か (2) の好きな方を選んでください
雑なまとめてですが、楽だからと思って親側の <dependencyManagement> にたくさんバージョンを書いて、子側からそれを参照してきたのですが、その辺りも重なって mvn spring-boot: 系のコマンドが上手く動かなかっただけ、という話でした。
これだけ長文でツラツラ書いてきましたけど、最初から 4-2 (2) のように親は <module> と、真に共通の設定だけ列挙して、依存管理などは別のモジュールでやるようにするという真っ当な方法でビルドしていれば起きなかった問題だということになりますね。
私ったらウッカリさん、てへぺろ。
そんなわけで、このブログが子pomから親pomを参照している人たちに届くことを祈っております。